这次我会带来一个pandaTV竹子Top20的教程,从零开始。
- python库:requests、pymongo等
- 开发环境:python3.5、windows10
- 数据库:mongodb
- 数据可视化工具echarts.js
- 抓包分析工具fiddler
- 一个虚拟主机或者github pages
- 首先我们要抓取数据(主播id和竹子数),那么我们就要抓包分析。
- 当我们知道从哪里可以获取数据后,就要写爬虫。写爬虫的时候要考虑以下问题,比如并发,增量等。
- 当我们抓取到所需数据时,我们需要保存数据,我们使用了数据库(其实是杀鸡用牛刀了)。
- 现在我们要根据需求来提取分析数据了,然后返回我们需要的数据。
- 得到所需数据后,我们要展示这些数据,要使用一些数据可视化工具。
- 写好展示页面后,我们要将它部署到网站上去,会讲到一些方法。
我们先分析一下需求,我们希望得到的数据:
- 因为pandaTV房间号是不固定的,我们要先获取热门直播里面的前20个主播的房间号。
- 得到房间号以后,我们要得到每个房间号里的主播id和竹子数量。
如果不想抓包分析,那可以直接使用selenium,但是selenium是万不得已才会用的,我第一次写的版本就是selenium版的,运行速度很慢。因为它的原理就是模拟人控制浏览器,要一个一个点开网页。
那么我们接下来开始抓包分析,pandaTV使用了ajax,我们使用开发者工具来抓包分析一下。放上chrome开发者工具教程
我们打开F12,点到Network标签,把preserve log钩打上,下面的选择XHR,开始抓包分析。我们先输入网址 www.panda.tv,然后点全部,然后随便选个房间进去,此处以我的房间为例。
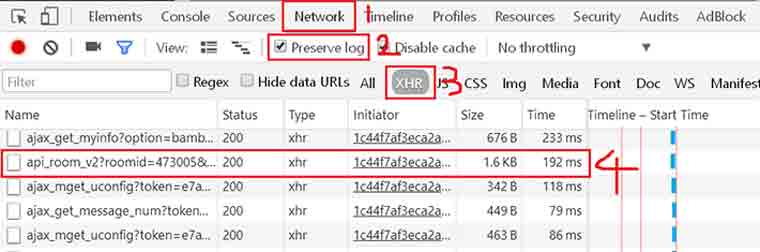 这里我直接给出需要的地址,即第4步的地址,其他的地址暂时不需要。那么网址格式大概
这里我直接给出需要的地址,即第4步的地址,其他的地址暂时不需要。那么网址格式大概"http://www.panda.tv/api_room_v2?roomid=" + 房间号, 比如 http://www.panda.tv/api_room_v2?roomid=473005
我们直接访问这个网址,得到json格式的数据,里面有我们需要的主播id和竹子数。
那我们得到了输入房间号返回数据的地址,接下来我们要获取热门直播的地址,那网页版是无法获取的,我们需要抓取Android客户端的api,这里用到的工具是fiddler,给出fiddler教程
为了节省时间,我直接给出我们需要的地址。pageno是页数,pagenum是每页多少人,同样得到json格式数据。
http://api.m.panda.tv/ajax_live_lists?pageno=1&pagenum=20&status=2&order=person_num
还有一个Github上的非官方API,也挺不错的。pandatvAPI
我们根据Android客户端抓取到的url获取房间号列表
1
2
3
4
5
6
7
8
9
|
import requests
#得到推荐前20的房间号
def getTop20List():
top20List = []
url = "http://api.m.panda.tv/ajax_live_lists?pageno=1&pagenum=20&status=2&order=person_num"
info = ((requests.get(url)).json())["data"]["items"]
[top20List.append(data_id["id"]) for data_id in info]
return top20List
|
那么我们再分析一下,因为这是当前的热门直播前20,主播的作息时间是不固定的,所以我们涵盖不了所有的主播。那么我们要实现增量抓取,即每次爬取的房间号要保存下来,这样反复几次,可以涵盖几乎所有的热门主播。这里我们使用pickle,这是一个很方便的库,方便的保存读取房间号列表,然后实现增量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import pickle, os.path
#记录爬取的房间号
def recordRoomList(roomNumberList):
with open('roomList.pickle', 'wb') as f:
pickle.dump(roomNumberList, f)
#读取文件中的房间号
def readRoomList():
with open('roomList.pickle', 'rb') as f:
roomNumberList = pickle.load(f)
return roomNumberList
#增量判断
def incrementRoom(roomNumberList):
if(not os.path.isfile("roomList.pickle")):
recordRoomList(roomNumberList)
return roomNumberList
existRoomList = readRoomList()
for item in roomNumberList:
if(item in existRoomList):
continue
else:
existRoomList.append(item)
recordRoomList(existRoomList)
return existRoomList
|
现在我们得到了房间号列表,根据我们抓包分析得到的地址,一个一个地请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import requests
#得到该房间的主播id和竹子
def getBambooAndName(roomNumberList):
roomInfoList = []
prefix = "http://www.panda.tv/api_room_v2?roomid="
for u in roomNumberList:
singleRoom = []
singleRoom.append(u)
info = (requests.get(prefix + str(u))).json()
if(info):
print(info['data']['hostinfo']['name'])
singleRoom.append(info['data']['hostinfo']['name'])
singleRoom.append(round(int(info['data']['hostinfo']['bamboos'])/1e6, 2))
else:
singleRoom.append(["none", "none"])
print("not get")
roomInfoList.append(singleRoom)
return roomInfoList
|
请注意,此处我并没有简单地用两个list,而是使用了list in list的形式。why?这是因为为了后面的数据库而设计的。我这里的形式是[[room1],[room2],...]
首先需要安装mongodb数据库,然后我们语言是python,所以使用pymongo库。
pymongo教程
我们要以字典形式存储进数据库,而且要先设计好数据库,我的设计如下。
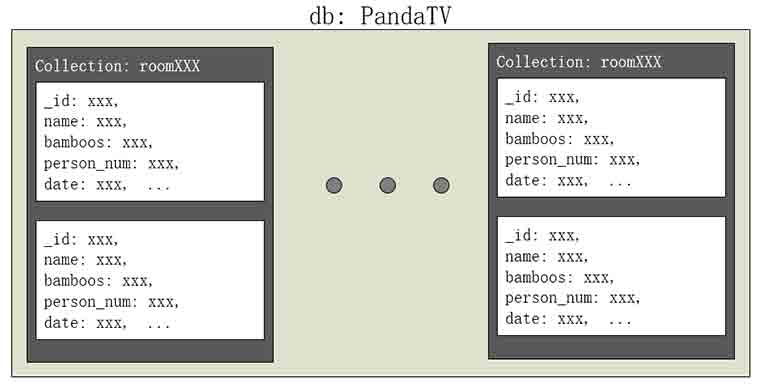
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
from pymongo import MongoClient
from datetime import datetime
#获取字典形式
def getDict(roomInfoList):
roomInfoDict = {}
for item in roomInfoList:
singleRoom = {"name": item[1], "bamboos": item[2], "date": datetime.utcnow()}
roomInfoDict["room" + str(item[0])] = singleRoom
return roomInfoDict
#存储到mongodb
def saveToMongo(roomInfoDict):
client = MongoClient()
db = client.pandaTV
for k,v in roomInfoDict.items():
collection = db[k]
collection.insert(v)
client.close()
|
最终存储进mongodb的数据是这样的,我们给每个post都加了一个:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
> show collections
room10003
room10009
room100130
room10015
...
> db.room7000.find()
{ "_id" : ObjectId("57a2f91deccca320542a9e64"), "bamboos" : 21.4, "date" : ISODate("2016-08-04T08:13:16.973Z"), "name" : "LPL熊猫TV官方直播" }
{ "_id" : ObjectId("57a2ff93eccca31b38213ac1"), "name" : "LPL熊猫TV官方直播", "date" : ISODate("2016-08-04T08:40:51.872Z"), "bamboos" : 21.4 }
{ "_id" : ObjectId("57a45105eccca305c45cb33a"), "bamboos" : 21.64, "name" : "LPL熊猫TV官方直播", "date" : ISODate("2016-08-05T08:40:37.707Z") }
{ "_id" : ObjectId("57a5c283eccca30f6c94b0a0"), "bamboos" : 22.04, "name" : "LPL熊猫TV官方直播", "date" : ISODate("2016-08-06T10:57:07.491Z") }
...
|
这里要注意有个坑,需要先安装mongodb数据库,在运行爬虫之前,需要先开启数据库。
关于这部分比较简单,大致就是读取数据库,按照时间戳来排序,得到最新的数据,然后返回Top20的一个Dict。特别需要注意的是,因为python的dict类型是无序的,所以即使你是排好序逐一添加,最后的Dict也是无序的。那么又因为我的Dict结构要方便数据可视化工具echarts.js读取,所以我设计成这样:
1
2
3
4
|
Dict = {
"name": ['xx', 'xx', ...]
"bamboos": [xx, xx, ...]
}
|
我直接把有序的列表作为values,这样就可以不关注Dict的坑了。还有就是要两个列表组合排序的问题,我使用了zip和sorted。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from pymongo import MongoClient
import json
def writeJsonFile(data,filename):
with open(filename+".json", 'w') as f:
json.dump(data, f)
def get20Rank(db):
bamboosList = []
nameList = []
rankDict = {}
mycollections = db.collection_names()
for item in mycollections:
latest = db[item].find().sort('date',-1)[0]
bamboosList.append(latest["bamboos"])
nameList.append(latest["name"])
bamboosList, nameList = zip(*sorted(zip(bamboosList, nameList), reverse=True))
rankDict["name"] = nameList[0:19]
rankDict["bamboos"] = bamboosList[0:19]
writeJsonFile(rankDict, "bamboos_rank")
|
这样我们得到了包含数据的json文件。
关于数据可视化的选择有很多,web方面有highchart、echarts、d3之类。因为看中文爽,还是用了echarts。
echarts官网
我们需要异步加载数据,异步加载实例
这边还有个坑,就是因为x轴的数据太密集,会导致显示不全,解决办法:
1
2
3
4
5
6
|
xAxis: [
axisLabel: {
interval: 0,
rotate: 340
},
]
|
我使用了viewport来稍微支持了下移动端,即判断innerWidth的大小(显示屏)来设置参数。当屏幕宽度大于500px时,横向排版;小于500px时,纵向排版。
我们在调试echarts的时候,会遇到一个坑,即不能跨域,因为我们是读取本地json文件的。我安装了一个xampp来调试,比较方便。
因为我有一个配置好的虚拟主机,所以直接将json文件和html页面放上去就可以看到了。如果只是一个单纯的服务器,需要自己搭建服务器。或者放到github pages上也可以。
放上Github地址: panda-bamboos-rank
展示地址: http://behappy.cc/extension/panda/rank.html
PS: 由于熊猫直播已倒闭,本项目不再维护,展示地址不可访问。
以上。
如果本文对您有帮助,欢迎打赏。
