今天,给大家推荐一门有趣的语言——python,相信大家一定不陌生。那么可以用来做什么呢,本文主要用于模拟登录并提取一些需要的内容,当然,再仔细研究的话,还可以写一些签到的小工具。 注:本文所用python版本为3.4.2。 所需工具:python3、requests库、Beautifulsoup库。 首先,先从模拟登录的原理开始,主要讲post。 当登录一个网站的时候,相当于你带着一堆数据去访问一个网址,就像带着一堆见面礼去拜访某人家里。这里的见面礼就是一些headers,data和一些必要的数据,有些主人呢,不需要带什么见面礼就会给你开门招待你,就是无需登录的网站。有些主人呢,需要看中你的见面礼才会给你提供饭菜啊什么的,就是需要输入一些身份验证的数据才行,如登录。 当我们用浏览器登录时,我们只需要输入网址,输入账号密码就行了,浏览器会自动帮我们提交的,当然我们可以用python这门语言来实现伪装成浏览器提交数据。 大致过程如下:发送数据给网站,网站接收到,成功匹配,回应数据给请求者,提取内容。 那么我们到底要发送哪些数据给服务器呢?答案是按实际情况来找。就像上面所提的,或许你什么都不用带就可以访问,或许你要带一大堆东西才能访问。后面,我们会找个简单的示例,现在先来简单介绍一下requests库和beautifulsoup库。
1.requests
简而言之,这个库就是用来替我们发送接收数据的,非常强大的库。以前的模拟登录用的是urllib2(py2.x版本),urllib.request(py3.x版本),有点复杂,有兴趣的朋友可以研究一下。完全使用方法可以找官方中文文档,此处仅介绍post使用方法:
|
|
2.BeautifulSoup
好了,接下来是Beautifulsoup这个库,是一个处理文档的很强大的库,如果到处都用正则的话,显然很累,所以这个库算是帮大忙啦!完全使用方法也请自行找官方中文文档,此处仅介绍提取标签内容:
|
|
那么接下来要完成模拟登录一个页面就很简单了,requests登录,BeautifulSoup提取。那么现在问题来了,(卖萌技术哪家强),我们需要发送哪些数据呢?在哪里能看到呢?本文以chrome浏览器为示例,F12调处开发者工具,在登录之前打开,下面以我学校查询打卡为实例。
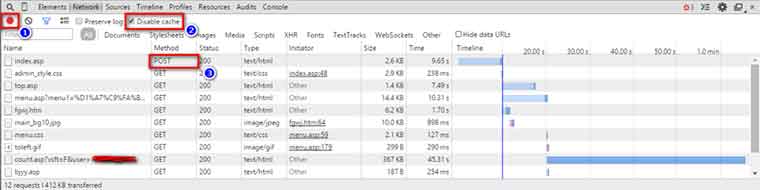
f12打开开发者工具,调到Network,保证①处红灯亮,②处是禁止缓存,接着输入用户名和密码,就会有许多东西跳出来啦,③处是找post,这里面才会有我们需要发送的数据。打开来看看呢
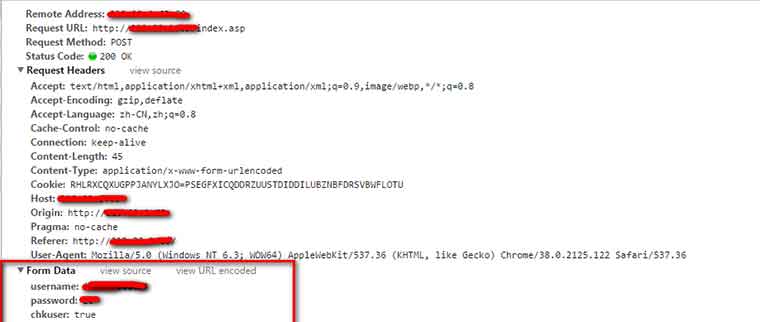
红框框里面就是我们需要发送的数据了,三个,算是比较简单了。有username,password,chkuser,密码也是明文的,所以只要post这几个数据给这个网址就行啦。以下是源码:
|
|
当然也可以print(soup.find_all('td')),不过打印的内容就比较多啦!
至于做百度自动登录,人人自动登录。post的数据密码都经过加密的,rsa算法和md5吧,需要更深层次的研究,以后做出来了再给大家分享吧。
以上。