时间过得真快,看了一下上次发文的日期,发现几乎快一年半没有更新博客了。这一年半,做了些事情,也荒废了些光阴,遇到了各式各样的人,收获良多。以后可能会把所得的感悟记录总结下来,不过这次的文章主要是关于技术方面的,也就不多嚼舌根了。
这次的内容如题,微信公众号爬虫。关于微信公众号爬虫,肯定之前就有很多解决方案了,毕竟有需求就有市场嘛。「这里」提供了大概4种思路去实现一个微信公众号爬虫,有兴趣的朋友可以深入研究一下。
可是无论是上面的哪种方式,都需要很复杂的流程和环境,而且随着微信的迭代更新,大部分的开源代码都失效了。然而我的需求很简单,仅仅只是爬取这个公众号所有的历史文章。经过一番折腾,我找到了比较简单的实现思路,分为两部分,浏览器开发者工具 + headless 爬虫。
“最简单”虽然有点标题党的味道,不过跟其他人的源码相比,我的代码肯定是最少的,因为只有两个js文件,连数据库都不需要安装。所谓鱼和熊掌不可兼得,我的思路代码少,但是也有缺点。第一个缺点是这种方式是半自动的,一次只能爬一个公众号。第二个缺点是功能目前仅限于爬取所有历史文章。接下来,我会用图文的形式讲解我的思路,详细的代码可以参考「此处」。注:此次演示所用公众号为「东京留学生活小助手」,..仅供学习交流,如有侵权,请联系我。..
1. 开发者工具提取网址
本次实验会利用到微信电脑客户端,Chrome浏览器。
第一步:首先我们打开微信电脑客户端,进入微信公众号,如图1所示。
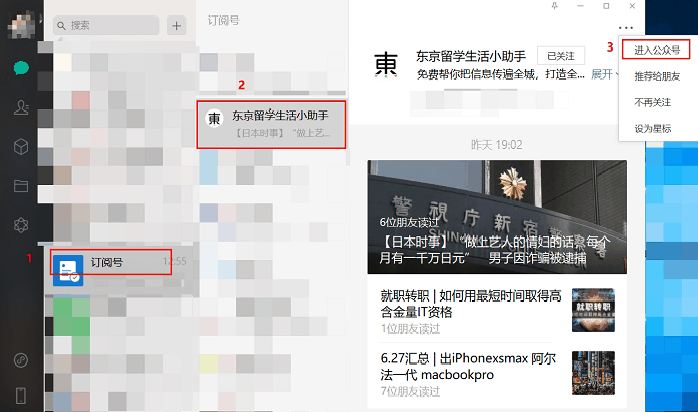
图1. 进入微信公众号
第二步:将微信设置-通用设置-使用系统默认浏览器打开网页选项点上,使得能用 Chrome 打开文章。然后是比较重要的一步,随便打开一篇文章然后关掉,目的是为了让浏览器获得相应的 cookie,否则的话,所有的文章都无法显示,只会提示“请利用微信客户端打开”。
第三步,还是点公众号右上角的三个点,选择查看历史消息,进入到历史消息页面,如图2所示。
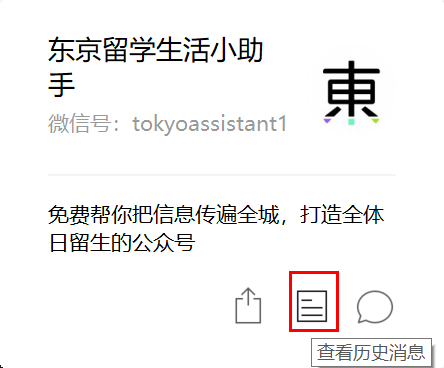
图2. 查看历史消息
第四步,按 F12 打开开发者工具,选中 Console 将 console-code.js 中的代码复制进去,按回车执行,效果如下面的动图所示。
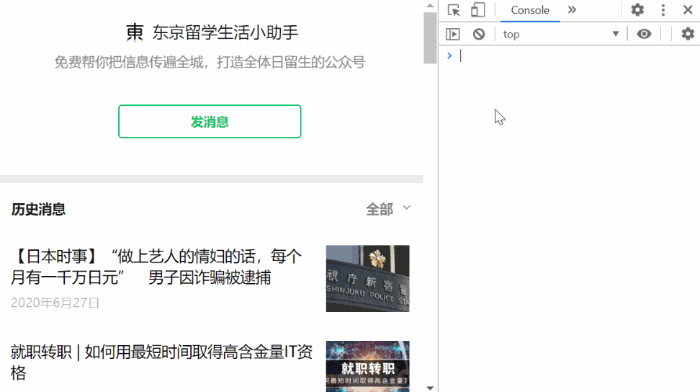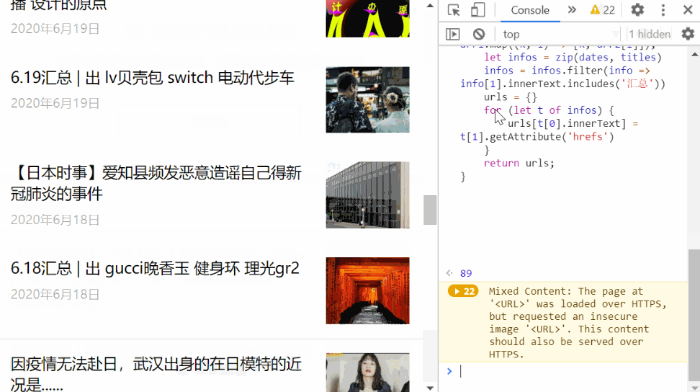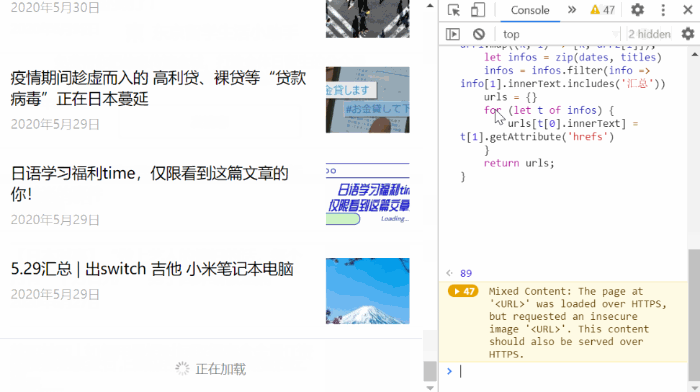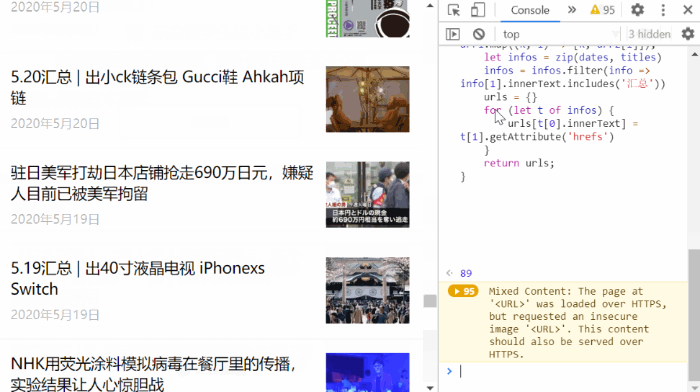
代码主要完成的任务是无限下滑直到已无更多出现,然后抽取出想要的内容,复制到剪贴板。代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
// 设置一个定时器,每一秒滚动到底部,让其自动加载新内容
with ({ copy }) {
t = setInterval(function () {
// 滚动到底部
window.scrollTo(0, document.body.scrollHeight);
// 当没有更多内容时,取消这个定时器
let noMore = document.querySelector('.js_no_more_msg');
if (noMore.style.display != 'none') {
clearInterval(t);
// 将抽取到的内容复制到剪切板,然后可以粘贴到任意的编辑器,我这里是复制到json文件里。
copy(getMyContent());
}
}, 1000)
}
// 根据网页设置CSS Selector,爬取所有历史文章的url
// 最好是以array或者object的形式,便于保存
let getMyContent = function () {
// 此处是我自己想要的内容,请更改。
let titles = Array.from(document.querySelectorAll('h4.weui_media_title'));
let dates = Array.from(document.querySelectorAll('p.weui_media_extra_info'));
const zip = (arr1, arr2) => arr1.map((k, i) => [k, arr2[i]]);
let infos = zip(dates, titles)
infos = infos.filter(info => info[1].innerText.includes('汇总'))
urls = {}
for (let t of infos) {
// 获取所有历史文章的链接
urls[t[0].innerText] = t[1].getAttribute('hrefs')
}
return urls;
}
|
第五步,新建一个 json 文件,ctrl + v 保存所有历史文章的网址。比如我这里是将获取到的所有地址保存到 urls.json 里了。
2. Puppeteer爬虫
Puppeteer 是一个 Chrome 官方出品的 headless Chrome node 库,具体见「这里」。简单来说,就是比selenium高级一点,用来模拟浏览器行为的工具。中文内容关于puppeteer的不多,简单快速上手我推荐这两篇文章。
具体的环境安装配置此处略过,配置完环境,直接运行node crawl.js即可。下面讲解一下代码思路。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
const puppeteer = require('puppeteer');
const urls = require('./urls.json'); //获取所有的url
const fs = require('fs');
(async () => {
// 打开一个新的窗口,此处我选择了可视化,让你知道发生了什么。
// 可以删除掉{headless: false}使程序在后台运行。
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
let articles = {};
// 遍历url
for (let k in urls) {
// 访问地址,等待加载
await page.goto(urls[k], {
waitUntil: 'domcontentloaded'
});
// 获取到自己想要的DOM
const content = await page.$eval('#img-content', node => node.innerHTML);
// 直接存储整个HTML结构,解析可以在后面做
articles[k] = content;
// 一秒一次访问,防止过快被封
await page.waitFor(1000);
}
// 写入json文件
fs.writeFile('articles.json', JSON.stringify(articles), encoding = 'utf8', (err) => {
if (err) throw err;
});
// 关闭浏览器
await browser.close();
})();
|
当运行完成之后,会生成一个 articles.json 文件,里面就是我们想要获取的内容。至于分析就是后面的事了,下一篇博客会简单地统计分析一下词频做个词云。至此,一个最简单的单个微信公众号爬虫就完成了,简单易懂,并且比较难失效。
如果本文对您有帮助,欢迎打赏。
